Chat
SMARTRIQS allows real-time communication between participants. Any number of participants in a group can participate in chat. The chat feature is highly customizable: researchers can set up multiple chat stages within one study, allow chat between certain participants only (e.g., based on role or decision), and add time limit to chat. Furthermore, researchers can customize the visual layout of the chat window (e.g., width, height, time format, instructions). Chat logs are saved in Qualtrics in a user-friendly format.
The CHAT block
Required variable
| chatName | The name of the embedded data variable in which the chat log will be saved. Participants will see this chat log and can submit their messages to this log. A convenient way is to name the chat after the participating roles and the stage. For example, if role A and role B are chatting in Stage 1: “chatLog_AB_1”. If there is only a single stage of chat and every role in the group is participating in it, you can simply name it “chatLog”. Note: when you define the chat log embedded data, it can’t be empty — you should put some placeholder text (for example “text”) in it. |
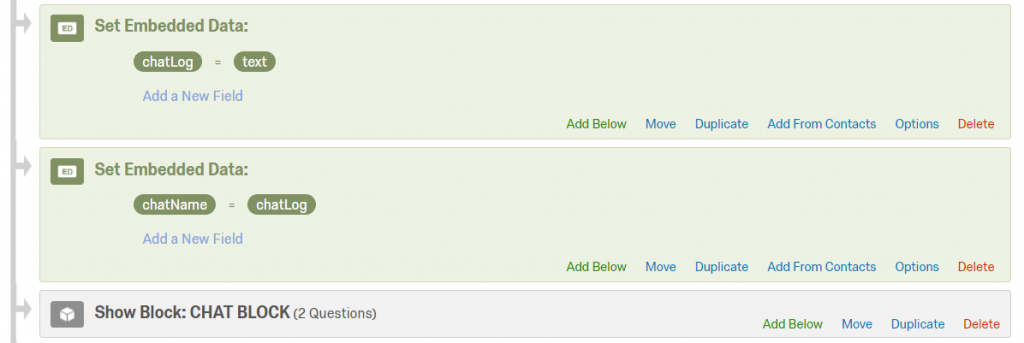
Optional variables
You can use the following optional variables to customize the chat:
| chatInstructions | Changes the instructions above the chat window to any string that you specify. Please avoid double quote characters (“) in this string. Double quotes break the script. Use single quotes ( ‘ ) instead. If this embedded data is not set, the default instructions are used (“Hit ‘Enter’ or the ‘Send message’ button to send a message.”) |
| chatWindowWidth | Use any integer between 400 and 1200 to define the width of the chat window, in pixels. If this embedded data is not set or invalid, the default value is used (600). |
| chatWindowHeight | Use any integer between 240 and 720 to define the height of the chat window, in pixels. If this embedded data is not set or invalid, the default value is used (360). |
| chatDuration | Use any integer between 10 and 600 to define the duration (time limit) of the chat, in seconds. A timer will be displayed, indicating the remaining time until the limit. The chat automatically ends and the study proceeds to the next stage after this limit. If this embedded data is not set or invalid, there is no time limit and the timer is not displayed: participants can chat as long as they wish (or quit the chat at any point). |
| allowExitChat | If this is set to yes, the ‘Exit chat’ button is displayed, even when there is a time limit, to allow participants to exit the chat before the time limit expires. If this embedded data is not set or invalid, the ‘Exit chat’ button is hidden. Note that if there is no time limit, the ‘Exit chat’ button is always displayed. |
| chatTimeFormat | Set the format of the time stamps. Possible values: hms24: hour-minute-second in 24-hour format; hms12: hour-minute-second in 12-hour format; hm24: hour-minute in 24-hour format; hm12: hour-minute in 12-hour format. If this embedded data is not set or invalid, the default format is used (no time stamps). |
Sample settings
Sample custom setting #1 — large chat window with timer
The first example shows the setup of a custom chat block with larger-than-default chat window (800 x 400 pixels), and a 5-minute (300 seconds) timer. The time stamps are formatted to 12-hour time format, and only the hour/minute is displayed. Since we did not define allowExitChat, the ‘Exit chat’ button will be hidden, and participants will not be able to quit the chat before the 5-minute timer is up.

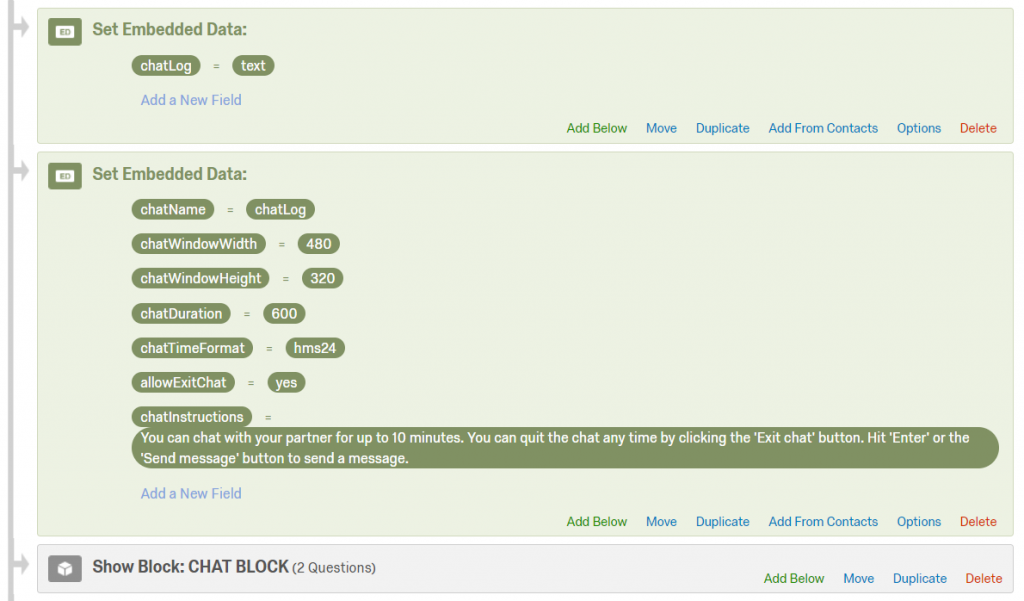
Sample custom setting #2 — small chat window with timer + custom instructions
In the second example, we use a smaller-than-default chat window size (480 x 320 pixels) and the 24-hour time format with seconds displayed. The timer is 10 minutes (600 seconds), and we allow participants to quit the chat before the timer is up. We also use custom instructions.

Sample custom setting #3 — chat interrupted by some other task
In this example two people chat (no time limit), then they do a task, and continue chatting.


Sample custom setting #4 — chat + other task + new chat
In this example two people chat (no time limit), then they do a task, and continue chatting. However, they start a new chat log after the task, so they don’t see their messages from before the task. We also use different settings for the two stages of chat (no timer before task, 2-minute timer after task).



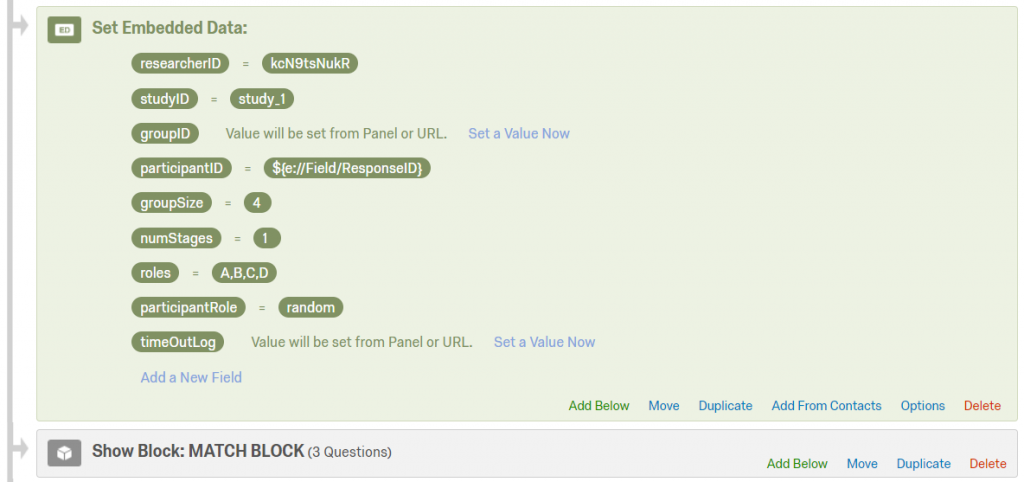
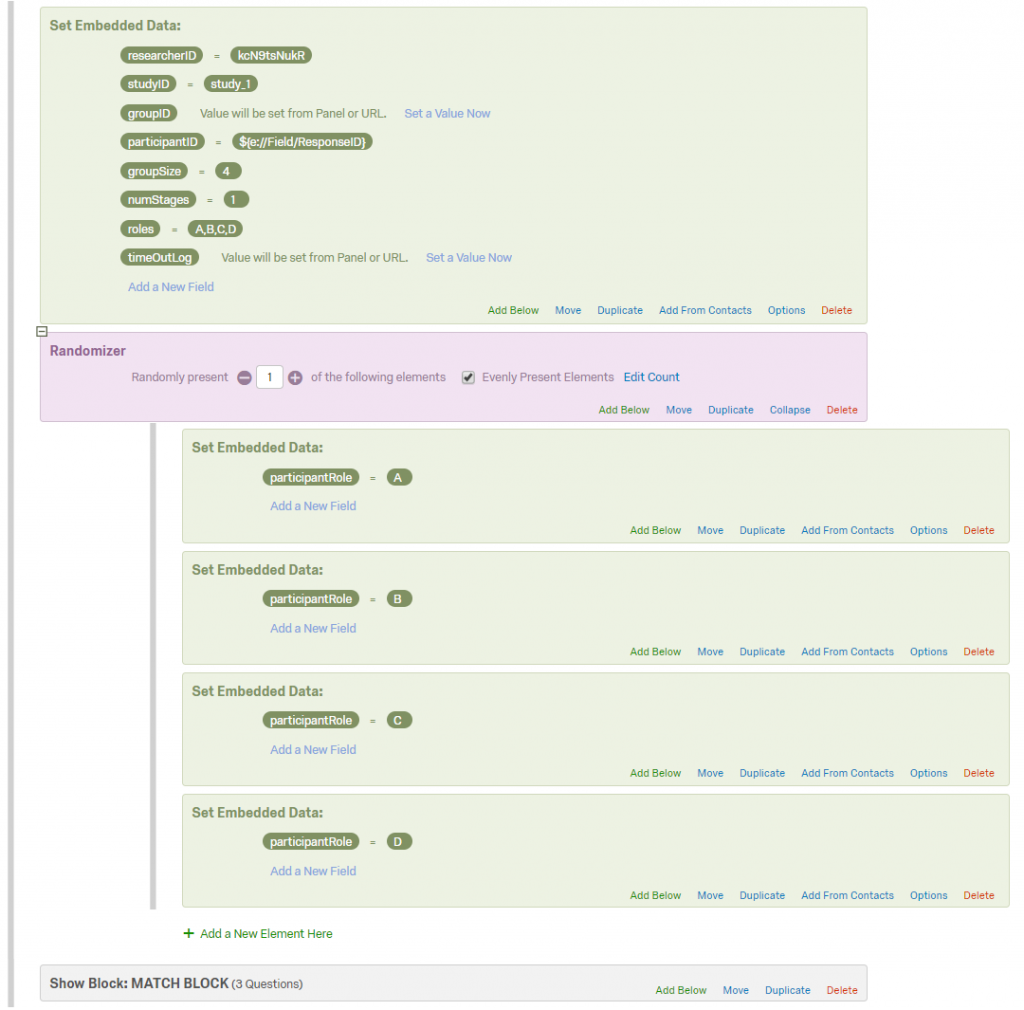
Sample custom setting #5 — private chat within group (A chats with B, C chats with D).
In this example there are four people in the group (A, B, C, D).
Instead of having a group chat, A chats with B, and C chats with D.
















 Note that responses are separated by commas
Note that responses are separated by commas